
Brug kunstig intelligens til at blive klogere på turister og destinationer (4/4)
Er der forskel på, hvordan par og børnefamilier tager billeder af Skagen? Hvordan bliver mad fotograferet i Sønderborg? Disse spørgsmål kan man svare på ved hjælp af kunstig intelligens, og i denne blog stiller vi skarpt på de værktøjer, du kan bruge til at analysere billeder selv.
Af Anders Munk, Henrik Halkier & Laura James, Aalborg Universitet
I tre tidligere blogindlæg har vi fortalt, hvordan vi har kortlagt #baredanmark kampagnen på Instagram ved hjælp af netværksanalyser og kunstig intelligens. I dette fjerde og afsluttende indlæg om sociale medier vil vi kigge bredere på, hvordan turismebranchen kan få gavn af de nye værktøjer til blandt andet billedanalyse, der i øjeblikket bliver mere og mere tilgængelige. Man kan selvfølgelig altid købe sig til hjælp hos konsulenter og vidensinstitutioner - men nu om dage kan man faktisk også selv bruge kunstig intelligens til at bliver klogere på sine gæster og sin destination.
Kunstig intelligens som genvej til ny viden
Det materiale, vi har arbejdet med i analysen af #baredanmark, er på mange måder typisk for de ustrukturerede og nærmest kaotiske datasæt, som flere og flere virksomheder og organisationer er omgivet af. De minder ikke om konventionelle kvantitative data i fx et regneark, men mere om den slags materiale man normalt vil analysere med kvalitative metoder. Det drejer sig især om tekster og billeder. Det nye er, at vi kan behandle denne type materiale maskinelt og i meget store mængder.
Kunstig intelligens har gjort det muligt at undersøge tekster og billeder på nye måder. Fordi vi efterhånden har meget store datasæt til rådighed, er det blevet muligt at ”træne” maskiner til at genkende mønstre i data og eksempelvis lære at skelne mellem negativt og positivt sprog eller identificere bestemte emner. I vores seneste blog brugte vi sådan en analyse til at geolokalisere opslag på Instagram ved at genkende stednavne i billedteksterne.
Automatiseret tekstanalyse har været tilgængelig for den almindelige bruger i nogen tid gennem forholdsvist let anvendelige værktøjer. Tekst er imidlertid ikke altid det mest interessante at undersøge. På et medie som Instagram spiller billedet fx helt åbenlyst hovedrollen. Det er ikke engang sikkert, at brugeren vælger at forfatte en billedtekst, og hvis det sker, kan det være på forskellige sprog samt af meget varierende længde og stil. Gennem de billeder, besøgende lægger op på Instagram, kan vi imidlertid på tværs af fx sproggrænser få en idé om, hvad det er for nogle motiver, der i deres øjne er værd at blive sat i forbindelse med.
På den måde er billeder også mere sammenlignelige end tekster på tværs af sammenhænge. Et billede taget på Grenen (Skagen) af en fransk turist kan for eksempel umiddelbart sammenlignes med et billede taget samme sted af en medarbejder fra Skov- og Naturstyrelsen. Motiverne vil formentlig afsløre, at de to fotografer har forskellige interesser, men begge billeder er taget på Grenen. Det ville ikke på samme måde være muligt at sammenligne deres tekster direkte, fordi de er skrevet på forskellige sprog.
Ved at undersøge mange billeder på samme tid kan vi finde mønstre i, hvad fotograferne interesserer sig for. Det kunne for eksempel handle om at finde ud af, hvordan forskellige grupper af besøgende afbilleder en destination. Er der forskel på, hvordan par, børnefamilier eller seniorer tager billeder af Skagen? Det kunne også handle om at finde ud af, hvordan et bestemt motiv finder forskellige udtryk på forskellige destinationer. Hvordan bliver mad eksempelvis fotograferet på restauranter i København? Og hvordan afviger det fra restauranter på Bornholm, gårdbutikkernes madmarkeder eller grillaftener i sommerhuset? I #baredanmark analysen fandt vi på den måde mønstre i de emner, som brugerne på Instagram associerede med kampagnen og dermed i det, de fandt Instagram-værdigt ved en sommer i Danmark.
Den slags analyser kræver, at vi kan behandle tusindvis af billeder automatisk, og til det har vi brug for en teknologi indenfor kunstig intelligens, der hedder computer vision. Heldigvis er computer vision indenfor de sidste få år blevet markant mere tilgængelig for den almindelige bruger. Services som Google Vision eller Clarifai leverer således relativt træfsikre algoritmer, der kan identificere motiverne på dine billeder på et splitsekund.
Kunstig intelligens - det handler om at træne rigtigt
Du kan prøve Clarifais version, som vi også brugte til #baredanmark analysen, her. Prøveversionen gør det muligt for dig at sende et billede, som du selv har valgt, til en af Clarifais modeller og se, hvad det er for nogle emner, den er i stand til at genkende. Du kan finde et billede på nettet i din browser, højreklikke på det og kopiere billedets adresse. Det giver dig en sti (url), som du efterfølgende kan kopiere ind i Clarifais prøveversion. Når vi bruger Clarifai til større undersøgelser, tilgår vi modellerne gennem en API, der gør det muligt at sende tusindvis af adresser afsted ad gangen ved hjælp af et script. Den mulighed giver prøveversionen ikke, men princippet er derudover det samme.
Hvis vi bruger Clarifais generelle model på et tilfældigt billede af ramsløg i en skovbund (se billede 1) kan vi med stor sikkerhed sige, at billedet er taget ude i naturen, at der ikke er mennesker på, at der er tale om et blad fra en plante og så videre. Vi ved ikke, at der er tale om ramsløg i en skovbund, men vi ved, at billedet er taget udendørs af en plante med blade om sommeren. Den generelle model er designet til at kunne håndtere alle typer billeder uden at være specialiseret i noget bestemt. Derfor er det også typisk nogle relativt overordnede indsigter, vi kan opnå om billederne på den måde.
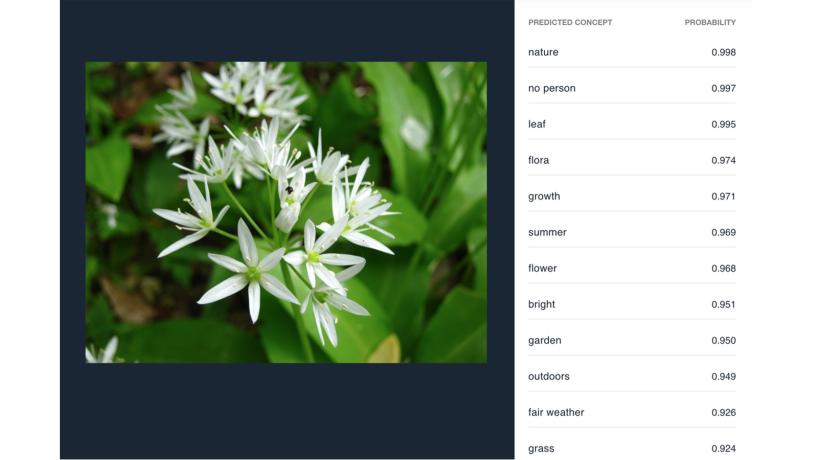
Billede 1: Billede af ramsløg tagget med Clarifais generelle model.Foto:WikimediaImages
Hvis vi derimod prøver at køre det samme billede gennem Clarifais specialiserede model for fødevarer (se figur 2) kan vi ret hurtigt konkludere, at der nok er tale om en spiselig urt af en slags. Modellen tror, det er fuglegræs, men foreslår faktisk også både ramsløg og toppen af en skorzonerrod som alternativer, den er mindre sikker på. Sandsynlighedsscoren til højre fortæller os således noget om, hvor sikker modellen er i sin sag. Eftersom der er tale om et gæt fra modellens side, og eftersom det gæt hviler på en sandsynlighedsberegning, er tags altid forsynet med en statistisk usikkerhed.
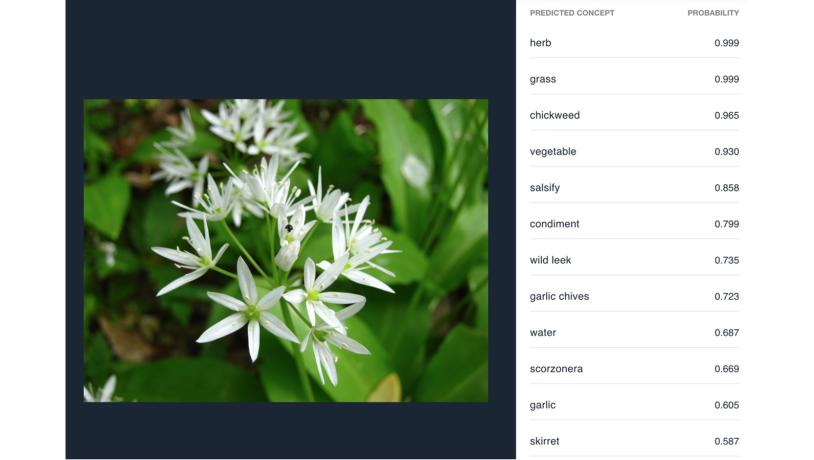
Billede 2: Billede af ramsløg tagget med Clarifais specialiserede model til fødevarerFoto:WikimediaImages
Grunden til, at der er forskel på resultaterne fra den generelle model og fødevaremodellen, skyldes forskellene på de datasæt, modellerne er trænet på. Den generelle model skal dække alle tænkelige motiver, og her har man prioriteret nogle mere overordnede forskelle, da man skulle træne modellen. For eksempel har modellen fået lov at øve sig på billeder taget henholdsvis udendørs og indendørs for senere at kunne lave den sondring. Med den specialiserede fødevaremodel har Clarifai derimod prioriteret at have træningssæt, hvor modellen kan øve sig på at skelne mere detaljeret mellem fødevarer. Så hvis man vil finde ud af, hvor udbredt interessen for New Nordic Cooking er, så er det en specialiseret model, man vil have glæde af - så den kunstige intelligens kan genkende fx ramsløg og havtorn.
Skab og træn din egen model
Hvis du har lyst til at prøve, hvad det vil sige at træne en model til billedgenkendelse, så kan du bygge din egen model med brug af dit webkamera her. Selvom det er i meget mindre skala, illustrerer værktøjet principperne i, hvordan en tjeneste som Clarifai bygger deres modeller. Du skal først og fremmest vælge nogle visuelle motiver, du er interesseret i at lære maskinen at skelne mellem. Herefter skal du give maskinen en masse eksempler på billeder, der indeholder de motiver (såkaldt træningsdata). Ved at analysere strukturen i pixels på billeder, der indeholder et bestemt motiv og ved at holde den struktur op imod billeder, der indeholder andre motiver, kan maskinen nu lære at genkende, hvilke motiver der er på billeder, som er ukendte for den på forhånd (såkaldt testdata). Du kan med det samme se, hvor meget træningsdata betyder. For det første er det kun de emner, du har fortalt maskinen om i træningsdata, der efterfølgende kan genfindes i testdata. For det andet har det afgørende betydning, hvor mange billeder maskinen har at øve sig på i træningsdata, og hvor forskellige de billeder er. Du kan for eksempel prøve at træne maskinen til at genkende din kaffekop og se, hvilken forskel det gør, hvis du kun tager billeder af koppen fra en vinkel, i forhold til hvis du har taget billeder af koppen i forskelle vinkler og situationer.
Med tjenester som Clarifai er brugen af denne form for superviseret maskinlæring blevet mere almindelig. Det betyder også, at det er blevet relevant at tænke over, hvad det egentlig kan bruges til.
Fire tips
- Sørg for at stille et spørgsmål, hvor det at kende indholdet på billedet, faktisk er interessant for dig. Superviserede maskinlæringsmodeller er gode til at se de forskelle, de bliver trænet til at se. Det er typisk konkrete forskelle i motivet, såsom hvorvidt der er mennesker på billedet eller ej, hvorimod det er sværere at træne modellen til at skelne mellem stemninger i et billede. Velegnede spørgsmål kunne for eksempel handle om, hvilke motiver en destination bliver sat i forbindelse med, eller hvordan motiverne varierer på tværs af sæsoner.
- Sørg for at have nok billeder til, at det ikke giver mening at kigge dem manuelt igennem. Mennesker er stadig langt foran computere, når det kommer til at fortolke indholdet af et billede. I vores analyse af #baredanmark-kampagnen skulle vi have kigget på næsten 40.000 billeder, hvilket ville have været praktisk umuligt. Her var kunstig intelligens et acceptabelt alternativ.
- Sørg for at sikre dig, at den model, du bruger, faktisk er trænet til at forstå de forskelle, du leder efter (gå til oversigt over Clarifais modeller). Som forskellen på billede 1 og 2 illustrerer, kan man af og til komme væsentlig længere med en specialiseret model, men samtidig ville fødevaremodellen i de fleste tilfælde være ubrugelig til at analyse rejsebilleder med familien.
- Hvis du skal træne din egen model, skal du ikke bare have adgang til meget store mængder billeder (typisk flere millioner), du skal også have adgang til billeder, der er tagget med den type information, du ønsker at lære modellen at genkende. Det vil i langt de fleste tilfælde være urealistisk, og derfor er pretrænede modeller, som Clarifai eller Google Vision, et godt alternativ. Her kan du få meget ud af at analysere et datasæt med nogle tusind billeder. Det kan enten være billeder, du selv ligger inde med, eller billeder, du finder på nettet. Hvordan afbilledes din destination for eksempel på rejseblogs verden over? Eller hvordan fremstår den på Google Image-søgninger i forskellige lande? Her vil du have brug for hjælp til at indsamle links til billederne fra de pågældende kilder, hvilket kan gøres relativt enkelt (hvis du ikke selv vil i gang med Python, eller kender nogen der kan hjælpe dig, så har Digital Methods Initiative i Amsterdam udviklet en række lettilgængelige værktøjer.
Takeaways
|